Private AI inference: what it means and how Chutes makes it verifiable
Timon Agar
Engineering and product team.
In our view the real question of what is private inference comes down to runtime access. Who can see prompts, outputs, weights, or runtime memory during execution? That is where our approach matters most: hardware-attested confidential compute, OpenAI-compatible APIs, and an optional end-to-end encrypted path for eligible workloads.
The term “private AI inference” is used too broadly. In some cases it means a dedicated endpoint. In others it means deployment inside your own cloud account. In others it refers to a trusted execution environment. These are related, but they solve different problems. Confusing them usually leads to the wrong buying decision.
A better way to evaluate the category is to start with access rather than labels. Can the provider inspect prompts while the job runs? Can an operator inspect outputs or model behavior? Can the runtime be verified, or are you being asked to rely on policy alone? Those questions matter more than whether the hardware is shared or reserved.
What private AI inference actually means
A serious private-inference setup protects data in use. Storage and transport still matter, but runtime exposure is the harder problem. Prompt content, output content, model weights, and the memory space where inference happens.
This is where vendor language often blurs important distinctions. One provider may use “private inference” to mean reserved capacity. Another may mean deployment in your VPC. A third may mean confidential inference backed by attestation and hardware isolation. Each can be useful. Each addresses a different layer.
The clearest distinction is this: buyers use “private inference” as the broad category. Confidential inference is the stronger technical subset. It relies on TEEs, remote attestation, and hardware isolation to narrow who can inspect data during execution.
Public inference vs dedicated inference vs confidential inference
Public or shared inference
- What it usually means: Shared multi-tenant API surface with standard platform controls.
- Main strength: Lowest friction and fastest adoption.
- Main weakness: Weakest privacy posture for highly sensitive workloads.
- Best fit: General workloads with normal privacy requirements.
Dedicated inference
- What it usually means: Reserved endpoint or isolated capacity for your workload.
- Main strength: Better performance isolation and predictable capacity.
- Main weakness: Reserved capacity alone does not prove prompt or memory protection.
- Best fit: Teams that need stable performance and enterprise deployment controls.
Confidential inference
- What it usually means: Inference inside a TEE or confidential-computing environment with attestation.
- Main strength: Strongest answer to runtime access concerns.
- Main weakness: More architectural complexity and narrower eligible runtime paths.
- Best fit: Regulated, high-trust, or IP-sensitive workloads.
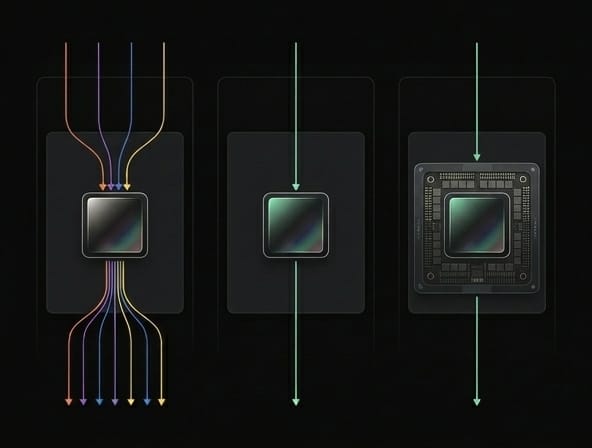
That comparison captures the core tradeoff. Dedicated infrastructure can improve isolation, but it does not by itself show that prompts are hidden from every operator path. A VPC deployment can improve network control and residency, but it still leaves the question of runtime exposure. Confidential inference is the category that tackles that question directly.
How our private AI inference works
Our advantage is that we do not have to rely on broad enterprise-security language. The platform is still easy to integrate: our shared inference endpoint is OpenAI-compatible at https://llm.chutes.ai/v1, and the live shared model list is available at https://llm.chutes.ai/v1/models. That matters because teams can adopt stronger privacy controls without rebuilding their client layer.
The stronger signal is in our runtime design. Our security architecture includes a TEE mode built around Intel TDX plus NVIDIA confidential-computing protections. We also document measured boot, remote attestation, encrypted root filesystem handling, and signed-image admission. That is more useful than generic “enterprise security” language because it states what is being verified and how.
In our public documentation, we show that the TEE path includes RTMR measurements during boot and a TD Quote signed by CPU hardware. We also describe validator checks against a known-good configuration, NVIDIA GPU attestation, a LUKS-encrypted guest root filesystem that unlocks only after successful attestation, and Kubernetes admission that permits only cosign-signed images. Those are concrete mechanisms.
We also document a stricter end-to-end encrypted inference path. In our March 2026 blog post and E2EE API reference, we explain that prompts are encrypted on the client, sent as ciphertext, and decrypted only inside a verified TEE. The response is then re-encrypted inside the enclave before leaving it.
That is the strongest privacy claim we make today, and it still needs to be scoped carefully. The accurate claim is not that all Chutes inference is end-to-end encrypted by default. It is that we support a stricter E2EE flow for eligible TEE-backed inference instances.
What we can say with confidence
There are four claims we can make definitively.
First, we support OpenAI-compatible inference for privacy-sensitive workloads. That lowers adoption friction.
Second, we have a substantive confidential-compute story rather than a generic security page. Our public material describes TEE mode, attestation, measured boot, image signing, and encrypted storage with more specificity than most vendor surfaces.
Third, we support a stricter E2EE path in which plaintext stays on the client until it reaches a verified TEE. For highly sensitive inference paths, that is our clearest product-level proof point.
Fourth, our documentation is explicit about limits. We do not present TEEs as a silver bullet; they still require software validation and auditability around them. That makes the overall position more credible.
How we compare with the broader market
Most competitors split the topic into two different stories. One is about enterprise deployment control: dedicated endpoints, BYOC or VPC deployment, plus promises around residency or retention. The other is about confidential computing: TEEs, attestation, hardware-backed isolation, and protection for models and data in use.
Few providers connect both stories clearly in one place. We think that gives us an opening.
Several vendors cover part of the conversation, but most present it through dedicated deployment, private networking, enterprise controls, or compliance. That includes Together AI, Fireworks, Modal, Replicate, RunPod, and SiliconFlow. The big cloud and research sources reviewed here provide stronger category material on confidential computing itself. That includes NVIDIA, Azure, Google Cloud, and Anthropic. Those sources are less useful, though, to a buyer trying to understand how a private inference API maps to an actual deployment decision.
We can bridge that gap by defining the category in plain language, showing the architectural tradeoffs, then connecting that explanation to OpenAI-compatible inference, TEE-backed execution, remote attestation, and an optional E2EE path.
Is Chutes OpenAI-compatible?
Yes. We provide an OpenAI-compatible inference endpoint at https://llm.chutes.ai/v1, along with a live models endpoint at https://llm.chutes.ai/v1/models.
Sources
Primary references for this piece include our quickstart (https://chutes.ai/docs/getting-started/quickstart), LLM chat docs (https://chutes.ai/docs/examples/llm-chat), security architecture (https://chutes.ai/docs/core-concepts/security-architecture), E2EE API reference (https://chutes.ai/docs/api-reference/e2e-encryption), and our March 2026 E2EE blog post (https://chutes.ai/news/end-to-end-encrypted-ai-inference-with-post-quantum-cryptography).
Related Articles

End-to-End Encrypted AI Inference with Post-Quantum Cryptography
Mar 26, 2026

Why Does AI Need GPUs?
Oct 28, 2025