I built an open-source TEE stack for confidential GPU compute

Kyle Widmann
Engineering and product team.
The Journey
When your GPU workloads run on hardware you don't own, operated by people you have no reason to trust, you need the hardware itself to enforce privacy. That constraint is fundamental to decentralized compute. Chutes AI is a serverless GPU platform running workloads across a network of independent miners and operators, and I spent the last 9 months building open-source TEE infrastructure there to address exactly that.
The work was harder than I expected. Getting multi-GPU passthrough into confidential VMs was the first hurdle. Then came the question of how to manage workloads across hundreds of independent GPU clusters while maintaining security. Cluster management typically requires access that could expose user data. We needed to orchestrate operations without creating openings. I had to make a fundamental architectural change to a production system without causing downtime for existing miners. And I needed to manage stateful upgrades across distributed encrypted clusters without manual intervention to reduce the attack surface.
This post walks through the full engineering story. I’ll cover what worked, what didn’t, and where the real trust boundaries still sit.
The State of TEE Claims
TEE claims are everywhere right now. Across decentralized infrastructure and GPU compute platforms, “TEE-secured” has become a checkbox on a features page. The term has been diluted to the point where it communicates far less than most readers assume.
TEE attestation gives you a cryptographic measurement of the software loaded into the enclave, produced by the hardware itself, verifiable against the hardware vendor’s API. It provides strong evidence that the enclave runs on authentic TEE-capable hardware and that specific code was loaded. But it doesn’t tell you what that code does, how the guest VM is configured, what workload isolation looks like, or where the trust boundaries are. Without inspecting those things independently, a TEE claim is still a “trust us” claim. The attestation measurement is only useful if you can independently verify what it should be.
Open source is a practical prerequisite for any credible security claim. Without source access, you can’t reconstruct expected measurements, can’t confirm there are no host-to-guest access paths, and can’t verify that the provider hasn’t built in data extraction mechanisms. Source availability alone isn’t sufficient. Reproducible builds represent another essential pillar, and we are actively working on providing them. But without source access, the verification loop can’t even begin.
We deliberately open-sourced the entire TEE stack at Chutes. The attestation layer, VM configuration, cluster setup, workload admission policies, and management infrastructure are all public. Anyone can audit what runs inside the enclave and confirm there’s no mechanism for us to access user data. This comes with real costs. Adversaries can study the system in detail, and every design decision is visible. We accepted those costs because asking users to take our word for it defeats the purpose of building on TEE.
GPUs in the Secure Enclave
Not all TEE implementations provide the same guarantees, and the differences matter more than most people realize. Some implementations produce a valid CPU attestation quote confirming a workload runs inside a hardware-protected enclave, but the GPU and its memory sit entirely outside that boundary. That means model weights, input tensors, and intermediate activations are accessible to whoever controls the host. Other approaches run workloads within a TEE but provide no way to verify what the guest VM actually consists of. You get attestation without assurance about what’s running inside or whether host-to-guest access paths undermine the isolation.
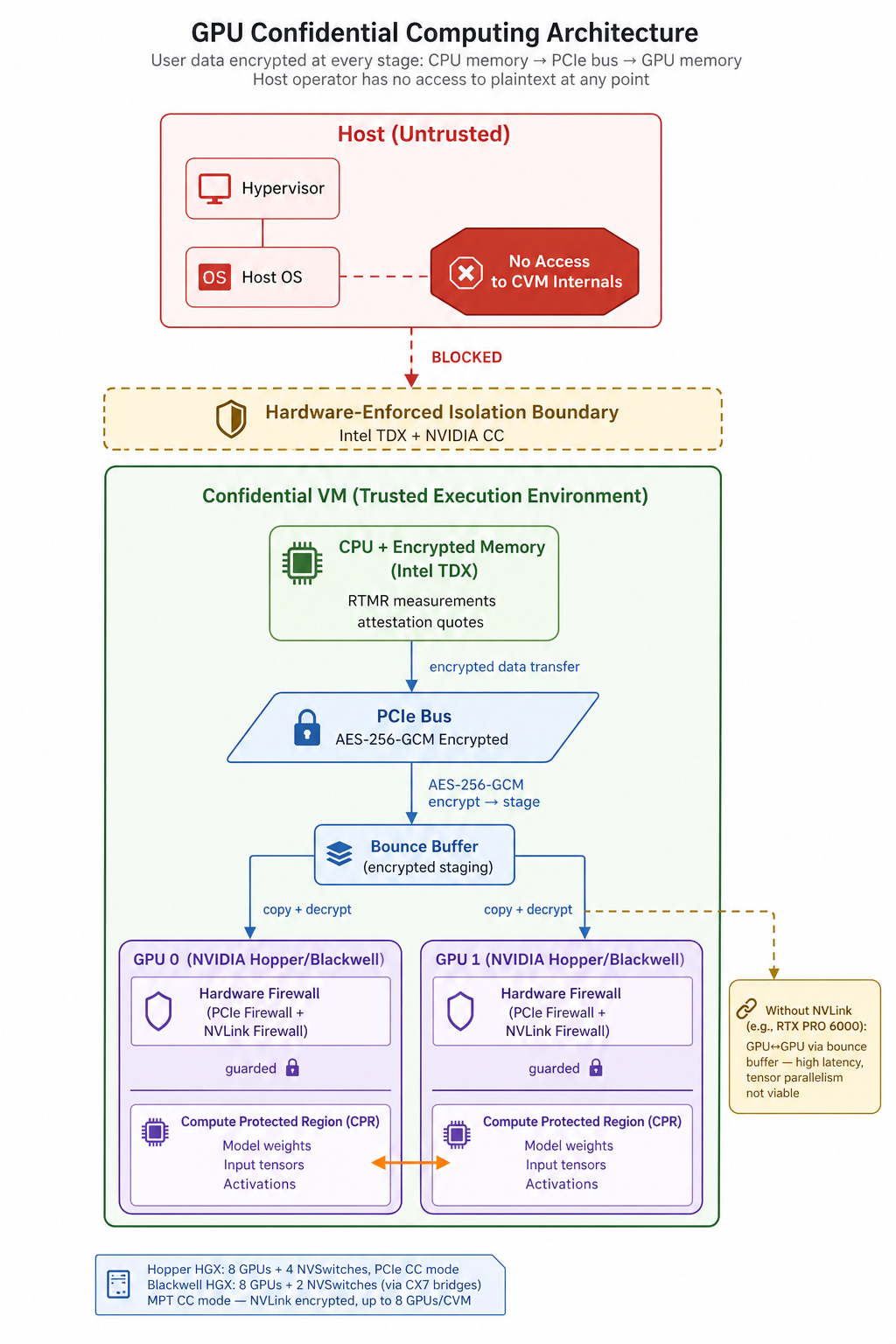
Extending the trust boundary to include GPUs requires NVIDIA’s Confidential Computing capabilities, and the specifics vary across hardware generations. On Hopper, single-GPU passthrough (SPT CC) gives you one GPU per confidential VM with encrypted CPU-GPU transfers, but no multi-GPU support. For multi-GPU on Hopper, PPCIe mode passes all 8 GPUs on an HGX baseboard into one confidential VM (CVM). The driver encrypts data with AES-256-GCM and places it in a bounce buffer, then the GPU copies and decrypts it into a hardware-firewalled Compute Protected Region (CPR). Two distinct mechanisms protect GPU data in this mode. Hardware firewalls inside each GPU enforce access control: the PCIe firewall blocks external access to the CPR, and the NVLink firewall prevents peer GPUs from reading protected memory. Data in transit over NVLink is unencrypted on the wire, but the NVLink interconnect runs entirely on the HGX baseboard with no software-accessible path from the host. The only way to intercept it would be a physical interposer on the baseboard traces, which NVIDIA considers out of scope for CC mode’s threat model. On Blackwell, MPT CC closes even this gap. NVLink traffic is encrypted, and you get up to 8 GPUs per CVM with the same bounce buffer encryption for CPU-GPU transfers. Our network also includes multi-GPU configurations without NVLink, like the RTX PRO 6000. These support multi-GPU passthrough, but all GPU-to-GPU communication goes through the bounce buffer.
These guarantees depend on the correctness of NVIDIA’s CC mode implementation, a trust dependency I’ll address in the section on trust boundaries.
Getting these modes working reliably across a heterogeneous miner network was where the real engineering started. The challenge was topology diversity. Each topology maps to a different CC deployment mode with different configuration requirements. Hopper and Blackwell HGX systems present their NVSwitches and bridge devices to the host in fundamentally different ways. These differences, multiplied across every supported configuration, add real complexity to dynamic topology management within a single VM image.
This created an early architectural question: maintain separate VM images for every hardware topology, or build a single VM that dynamically configures itself at boot? We chose the latter. One image discovers its hardware environment, detects GPUs and NVLink availability, selects the appropriate CC mode, and configures fabric manager and drivers accordingly. Building this was more complex than maintaining per-topology images, but it was far more manageable to deploy across a heterogeneous network of independent miners.
The real value of including GPUs in the secure enclave is extending confidential computing to where the most intensive computation actually happens. Without GPUs inside the trust boundary, model weights, input data, and intermediate activations in GPU memory remain accessible to the host regardless of what your CPU attestation says. But the engineering cost is real. You need to manage and test across every topology variant. There is also performance overhead from the confidential computing architecture. On configurations without NVLink, bounce buffer latency makes tensor parallelism (sharding a model across GPUs) unusable. Data parallelism works fine since each GPU processes independent batches, but everything requiring cross-GPU coordination must fit in a single GPU’s VRAM. These are the kinds of findings you only get by running real workloads in production configurations.
Problems in Sequence
With the GPU enclave established, the next set of problems was architectural. Getting GPUs into confidential VMs was a prerequisite. Building a production system on top required answering harder questions about how to organize, secure, and operate a distributed fleet of independently operated machines.
Federation vs. Unified Cluster
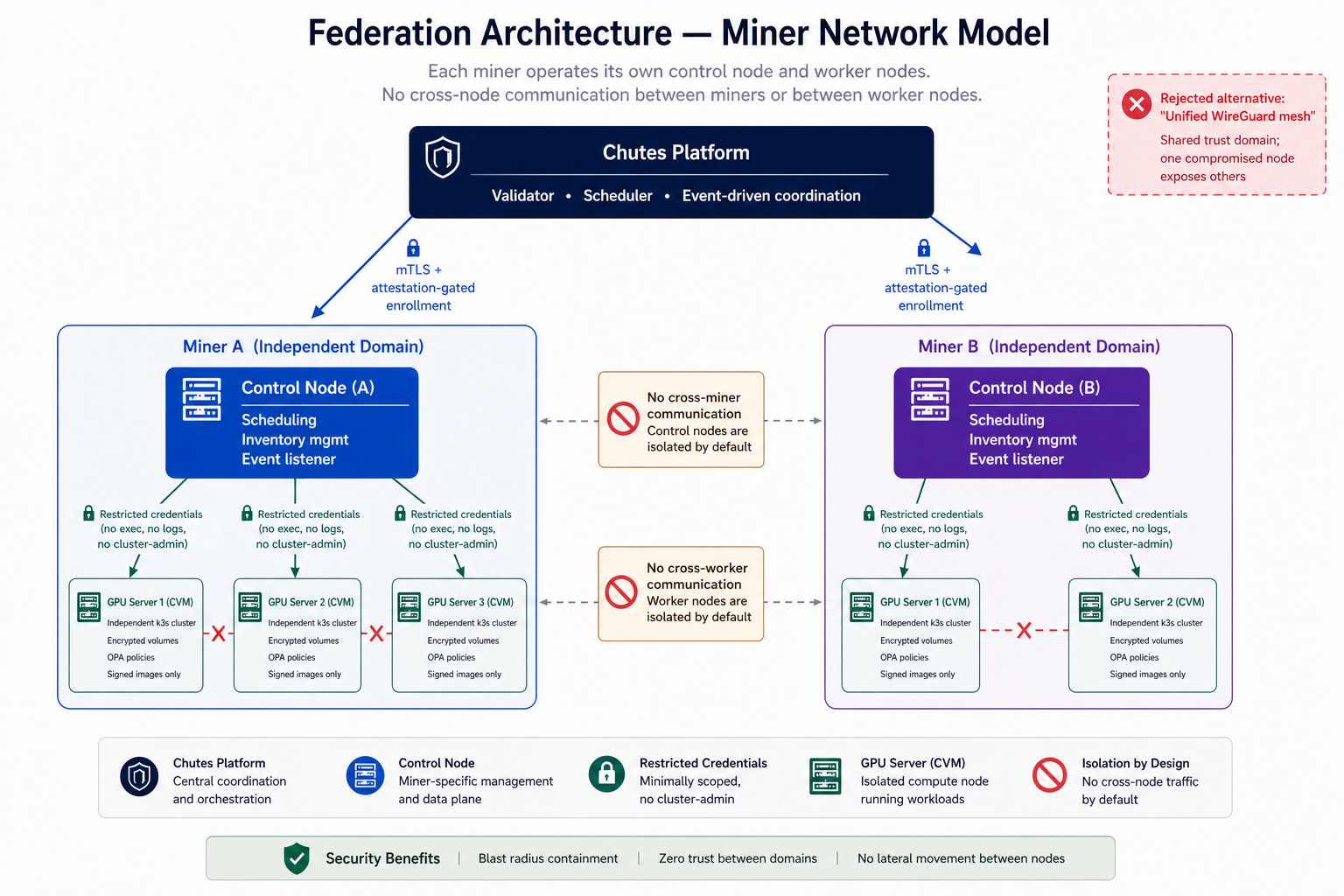
The first major architectural decision was how to connect the miner network. Either connect all miner nodes into a single unified cluster using something like a WireGuard mesh VPN, or treat each server as a standalone cluster and build a federation layer to coordinate them.
A unified cluster is appealing on paper. A single control plane simplifies workload scheduling. But our miners are spread across different data centers with different network topologies. This leads to CIDR conflicts, routing issues, and fragile WAN-linked control planes. These are solvable individually, but collectively they make the network brittle at scale. More fundamentally, the trust model is weaker. A unified cluster means every node shares a trust domain. One compromised node could potentially access workloads on others. When the hardware operators are untrusted by design, this is an unnecessary attack surface.
We chose federation. Each server runs as its own independent k3s cluster inside its confidential VM. TDX provides CPU isolation and attestation. NVIDIA CC mode secures the GPU. PPCIe encrypts the link between them. The platform orchestrates across these independent clusters. A compromised node is isolated by default. No shared control plane, no shared resources, no communication channel between nodes. Each node has its own credentials. The federation layer itself becomes the critical trust boundary.
We evaluated off-the-shelf federation solutions like Karmada, but they expected admin-level access to downstream clusters. Granting admin access defeats the purpose. You can’t lock down a cluster if the federation tooling requires unrestricted control. So we built our own. When a confidential VM is created, it generates miner credentials exposed via API. These credentials grant limited access to the working namespace: no exec into pods, no log access for workloads, no ability to modify cluster-level resources. This restriction operates at the Kubernetes API server level. It’s complemented by OPA policies running as an admission webhook, which enforce constraints on what’s admitted into the cluster. The two layers work together. API server RBAC limits who can do what. OPA limits what can be created even by authorized callers. The workload control subsection below covers OPA policies in detail.
The tradeoff is complexity. Federation means you need a secure, reliable way to coordinate across independent clusters for scheduling, health monitoring, and updates, without that coordination layer becoming a centralized point of trust or failure.
Securing the Federation Layer
Each standalone cluster needs to communicate with the platform. That communication channel is itself an attack surface.
Enrollment uses mutual TLS with attestation gating. A miner first registers for the subnet and stands up a control node, which manages scheduling based on an event-driven layer from the central validator. The miner then adds worker nodes, in this case confidential VMs running on bare metal. Attestation is enforced at boot, at network enrollment, and per-workload. The full attestation breakdown is covered below. The federation itself operates through the standard Kubernetes API using the restricted credentials described above.
This was a fundamental architectural change made to a live production system. We rolled it out incrementally so existing miners could adopt TEE without downtime or a cliff migration. The existing verification workflows were modular enough that TEE-specific attestation steps could slot in alongside the non-TEE path.
Workload Control and Image Signing
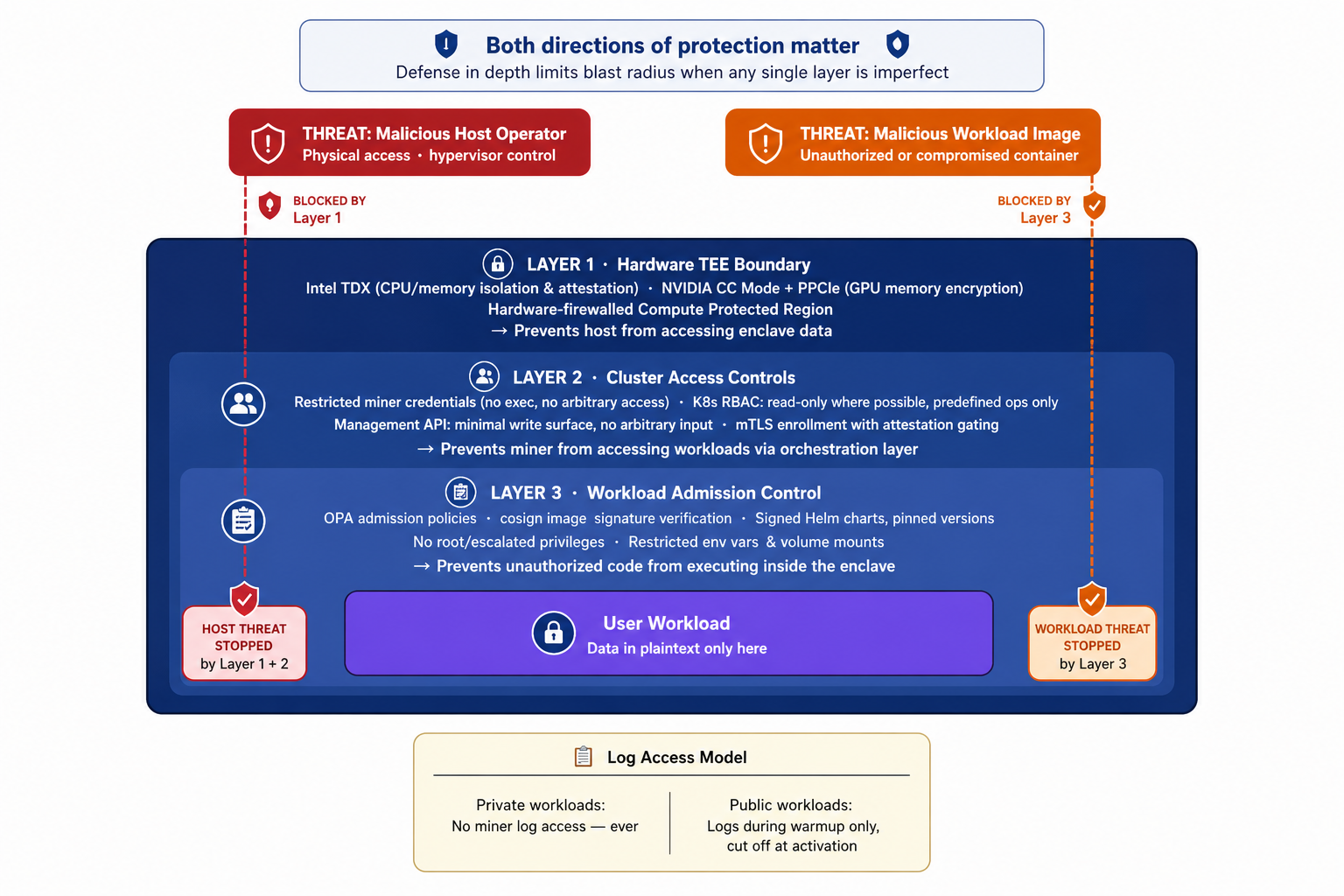
Even with a secure enclave on attested hardware, you still need to control what runs inside it. The enclave protects user data from the host operator. A malicious container image running inside the enclave is a threat from within the trust boundary. Both directions matter.
We use Open Policy Agent for workload admission control. The policies are specific and restrictive. We enforce cosign signatures on all container images, so only workloads built and signed by our build pipeline can run. The policies also enforce no root or escalated privileges in pods, no exec into pods, a predefined set of allowed environment variables, and restrictions on host and volume mounts. If a manifest doesn’t conform to the policy, the admission controller rejects it before anything runs.
For private workloads, miners have no log access at any point. Private workload data cannot be observed by the miner. For public Chutes workloads, miners can access orchestration-layer logs during warmup for health monitoring. Once the workload is activated and serving user requests, log access is cut off entirely.
This creates a defense-in-depth model. The TEE prevents the host from accessing data inside the enclave. Image signing and OPA policies prevent unauthorized code from executing within it. Together they address the two primary threat vectors: a malicious host operator looking in, and a malicious workload running inside.
The management API inside the cluster is read-only wherever possible, with write capabilities tightly scoped to predefined operations that reject arbitrary input. The full API and its constraints are in the open-source repos.
Encrypted Volumes and Stateful Upgrades
All persistent data within the TEE lives on encrypted volumes. This is fundamental to the security model. Without it, any CVM disk can be mounted and inspected when the VM is shut down, exposing sensitive data.
This created an operational challenge I hadn’t fully anticipated. Originally, k3s cluster state lived in the encrypted root filesystem. But when you upgrade a VM image, you replace the root filesystem and lose that state. So we transitioned k3s state to a separate encrypted volume that persists across VM upgrades, syncing during first boot.
This solved state persistence but introduced a new problem. How do you upgrade Helm charts and dependencies installed by the previous VM version? Exposing chart upgrades as a management API capability would mean components inside the VM are no longer deterministic. Anyone with API access could change what’s installed, and the running state would drift from what the VM version specifies.
The solution was to pin chart versions in the root filesystem. An automated service runs on boot, checks installed Helm chart versions in the persistent volume against what the current VM version specifies, and upgrades as needed without miner intervention. Version pinning and automated verification are part of the security model. They ensure what’s running within the enclave is deterministic and matches what’s published.
The upgrade process also must avoid leaving the system partially upgraded. If the VM restarts mid-upgrade, it must detect the incomplete state and either complete or roll back cleanly. We handle this through idempotent upgrade steps that can be safely re-run. Designing this correctly when everything lives on an encrypted volume requiring attestation-gated access at boot was one of the less obvious engineering challenges.
Attestation and Verification: What’s Actually Measured
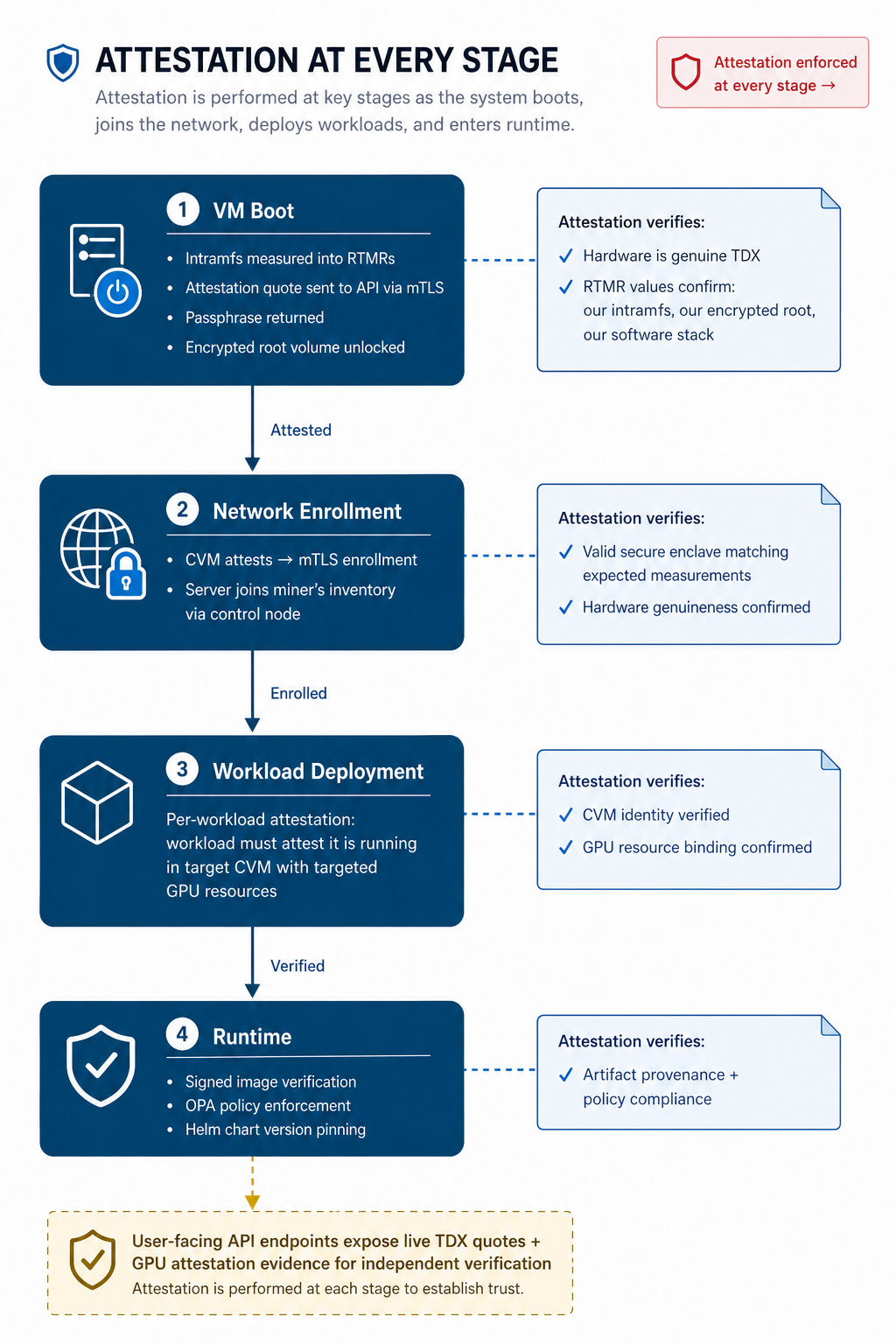
The attestation model ties everything together. Remote attestation means the confidential VM produces a hardware-signed quote (Intel TDX) containing measurements of what was loaded during boot. A verifier checks this quote against the hardware vendor’s API to confirm genuine TEE hardware, then inspects the measurements to confirm expected software was loaded.
Verification happens at multiple levels and stages. The platform verifies attestation at boot, where each CVM must pass to decrypt its root volume. It verifies again when the miner adds that server to the network. And it verifies per-workload: every deployment must individually attest that it is running in the target CVM with the targeted GPU resources. Attestation is not a one-time enrollment gate. It’s enforced at every critical stage of the machine’s lifecycle and at each workload deployment.
On the user-facing side, we expose live TDX quotes and GPU attestation evidence for CVMs and running instances via API endpoints. You can retrieve and inspect this evidence today.
The critical piece is boot integrity via initramfs. We use a custom initramfs to perform the initial encrypted root volume decryption. This matters because initramfs is measured into the RTMRs (Runtime Measurement Registers) during boot. The script in our initramfs is hardcoded to decrypt the root volume only after passing attestation against our API via mTLS. The API holds the passphrase needed to open the volume. If the attestation quote contains expected RTMR values, we have strong assurance the VM booted our initramfs, completed attestation, decrypted our encrypted root, and is running our known software stack. The initramfs source code and full boot chain are open source for independent review.
Inside the running enclave, we ensure artifact integrity through signed Helm charts and signed container images. Every workload and dependency must pass signature verification.
defense-in-depth-layers
attestation-boot-chain
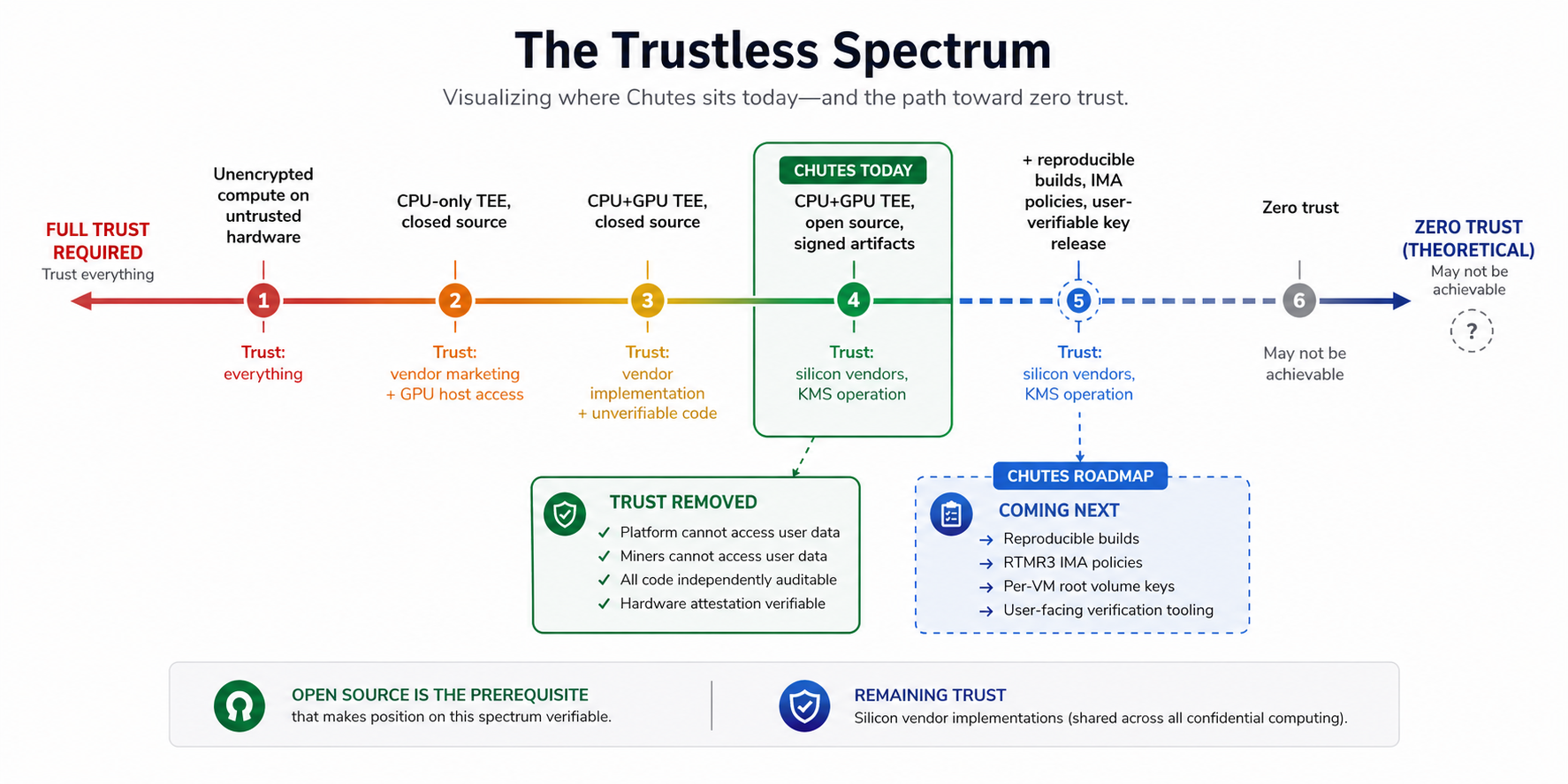
“Trustless” Is a Spectrum
After building this system, I think “trustless compute” is more accurately described as a direction than a destination. At some level, you are always trusting something. You’re trusting that Intel’s TDX implementation is correct. You’re trusting that NVIDIA’s CC mode and hardware firewalls work as documented. You’re trusting the attestation verification service operated by the hardware vendor. You’re trusting that AES-256-GCM remains computationally infeasible to break. These are reasonable assumptions, backed by substantial engineering and economic incentives. But they are trust assumptions nonetheless. No one has achieved truly zero-trust compute, and no one may ever fully achieve it.
What you can do is systematically remove unnecessary trust from the relationship. That’s what this entire project has been about. Today the stack includes GPU confidential computing with hardware-enforced memory encryption, remote attestation providing cryptographic evidence of the enclave state, signed and verified artifacts controlling what runs inside the enclave, encrypted volumes protecting data at rest, and an open-source codebase that makes all of this independently auditable. Each layer removes a category of trust that users would otherwise place in us or in the miners operating the hardware.
We’ve removed ourselves from the trust relationship in a meaningful way. The platform is architecturally prevented from accessing user data in transit or at rest within the enclave. The miners cannot access it because the hardware enforces isolation. The remaining trust boundaries are in the silicon vendors and their implementations. That dependency is shared across the entire confidential computing ecosystem.
We are actively improving the stack. We are working to provide reproducible builds to close the gap between auditable source and verifiable binaries. Adding IMA policies in RTMR3 to extend measurement coverage to artifacts running inside the enclave. Implementing per-VM root volume keys to improve resiliency. Providing user-facing attestation verification tooling so end users don’t have to take our word for any of this.
As I argued earlier, open source is the prerequisite that makes any position on the trustless continuum verifiable. That’s not the same as trustless, but it’s the only foundation we think is credible.
Try It / Explore It
The entire stack is open source. The core components live in two repos:
- TEE infrastructure, confidential VM, encrypted volumes, cluster bootstrap: github.com/chutesai/sek8s
- Confidential VM configuration
- k3s cluster setup
- OPA policies and image signing verification
- Encrypted volume management
- The initramfs-based boot chain described in this post
- Platform API, attestation verification, and documentation: github.com/chutesai/chutes-api
- Attestation evidence endpoints
- Verification guide
- API documentation
Nothing in this architecture is AI-specific. We built it for GPU inference, but the same TEE federation, encrypted volumes, and attestation model apply to any decentralized compute platform.
You can start verifying right now. We publish the exact measurements we accept for each hardware configuration via a public endpoint:
curl --location 'https://api.chutes.ai/servers/tee/measurements'
This returns the accepted RTMR values and expected GPU configurations for each hardware profile. The verification guide walks through the full process. It covers requesting attestation evidence, verifying TDX quotes, and validating per-GPU NVIDIA attestation.
If you have questions or want to contribute improvements, issues and pull requests are welcome. We’d rather have someone find a flaw in our implementation than miss it ourselves.